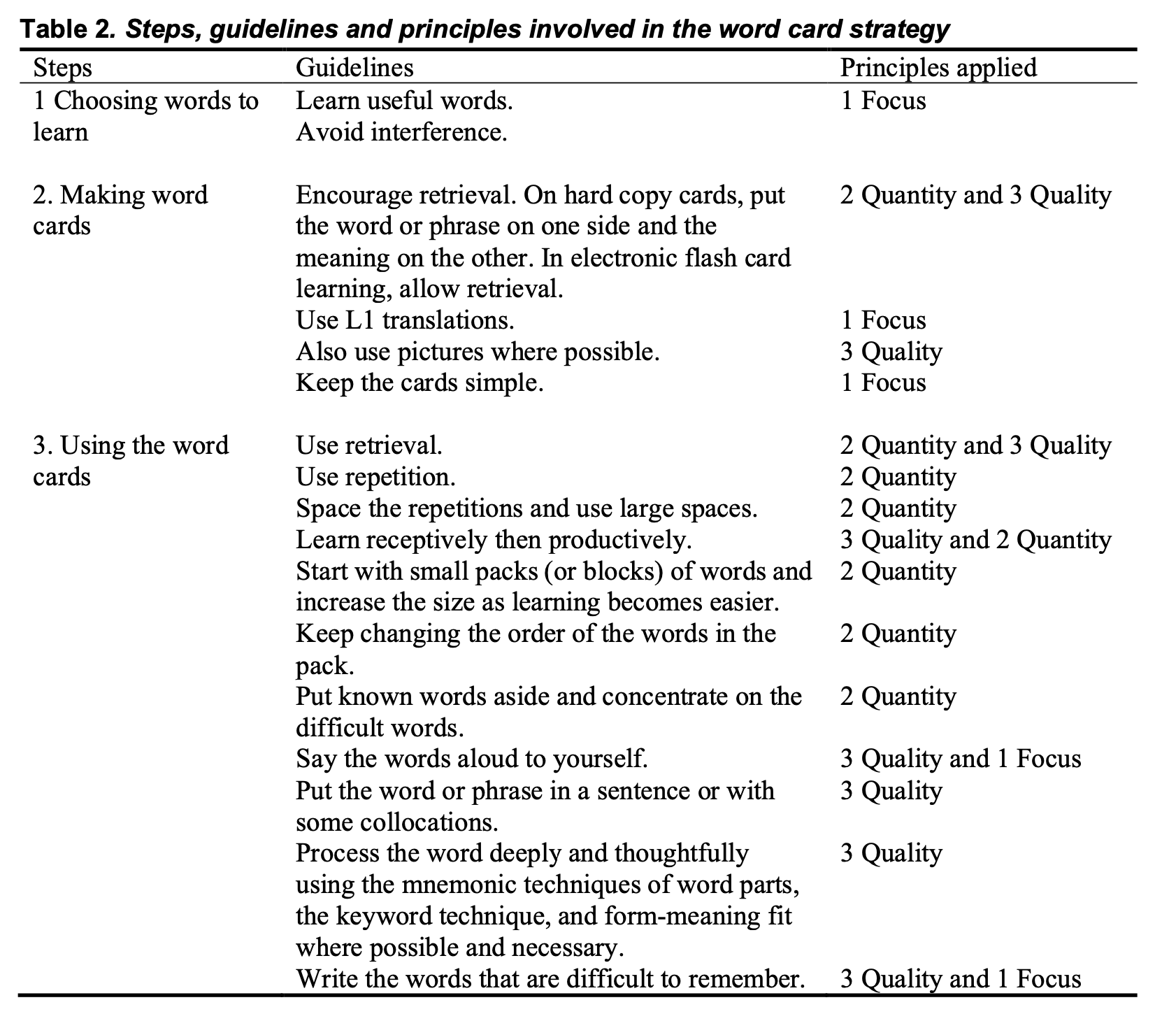
This article describes what could be in a course in training learners how to learn. It covers four strategies, repeated spaced retrieval, learning though use, deliberate learning, and mnemonic devices. Although the main focus is on language learning, the strategies can also be applied well beyond that, and examples are provided from learning vocabulary (learning items), learning economics (subject/content knowledge), and learning to drive a car (skill). The strategies are based on three principles of learning – focus of attention, quantity of attention and quality of attention. The article includes detailed instructions and tasks covering learning, application and analysis for running a workshop on learning how learn that can be used for a short intensive course or for including as a regular part of a teaching program. The tasks are ready to use with possible answers provided.
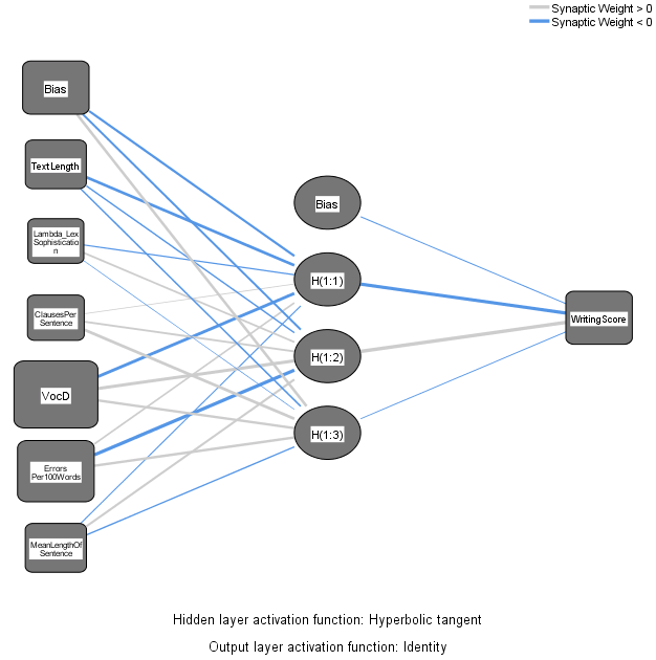
As one of the pioneering applications of machine learning for quantitative data analysis in applied linguistics, this study investigates the predictive power of linguistic features on English as a Foreign Language (EFL) writing quality. To overcome the limitations of traditional linear regression, specifically multicollinearity and non-normal data distributions, we employed a Multilayer Perceptron (MLP) neural network to analyse 96 essays from Chinese secondary school students. The model evaluated the relative predictive importance of various lexical, syntactic, fluency, and accuracy features. Demonstrating exceptional fit, the neural network accounted for approximately 80% of the variance in overall writing scores with no evidence of overfitting. Sensitivity analyses revealed that lexical diversity was the most robust predictor of writing quality (100% normalised importance), followed by grammatical accuracy (60.4%). Conversely, syntactic complexity, text length, and lexical sophistication exhibited comparatively minimal influence. These findings underscore the critical role of vocabulary diversity in evaluating adolescent EFL writing, while successfully establishing neural networks as a powerful, innovative methodological tool for future applied linguistic research.
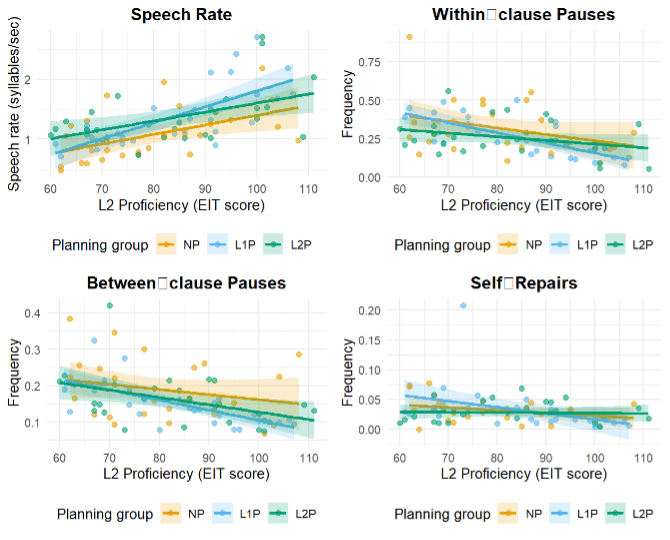
Pre-task planning is one of the widely used approaches to improve second language (L2) fluency in task-based language teaching (Ellis et al., 2020). However, the effect of the language used in pre-task planning on L2 speech fluency remains underexplored. The current study employed a between-participants design to compare the effects of planning languages at three levels: L1 planning, L2 planning, and no planning (a control group), across a narrative task on four measures of L2 speech fluency among 84 Chinese EFL learners. The study also investigated the moderating role of L2 proficiency. Results revealed that L1 planning significantly improved speech rate and marginally reduced between-clause pauses, while L2 planning showed weaker, marginally significant effects. Neither language of planning condition significantly affected within-clause pausing or repair fluency. In addition, within-group correlation analyses revealed that higher L2 proficiency in the L1 planning group was strongly correlated with all fluency measures. Pedagogical implications are discussed in terms of how to optimize L2 speech fluency in different planning languages across different L2 proficiency levels.